
웹크롤러를 이용한 Telegram Bot 미니미니프로젝트 만들기
Updated:
Telegram Bot with Web Crawler
이번 시간에는 python web crawler를 이용하여 웹페이지 상품정보를 가져와서 Telegram Bot과 연동하여 상품정보를 보여주는 미니 프로젝트로 웹크롤링에 대해 공부해보겠습니다.
개요
Selenium은 webdriver라는 API를 통해 브라우저를 제어할 수 있습니다. 또한 BeautifulSoup이란 라이브러리를 사용합니다. BeautifulSoup은 HTML, XML의 형식의 데이터를 다룰 때 사용합니다. 저는 런칭샵이란 사이트를 크롤링해보겠습니다.
런칭샵을 크롤링해서 python-telegram-bot모듈로 telegram bot과 커뮤니케이션할 수 있도록 합니다.
1. requirements
우선 프로젝트에 필요한 python 모듈을 설치해줍니다.
pip install selenium
pip install bs4
pip install python-telegram-bot
2. 상품정보 가져오기
우선, 크롤링하기 앞서 런칭샵이란 사이트에서 어떤 제품을 팔고 있는지 살펴봅시다.

페이지 밑에 전체상품을 보여주고 있습니다. F12 버튼을 눌러서 개발자도구를 통해 웹페이지 소스파일을 볼 수 있습니다.
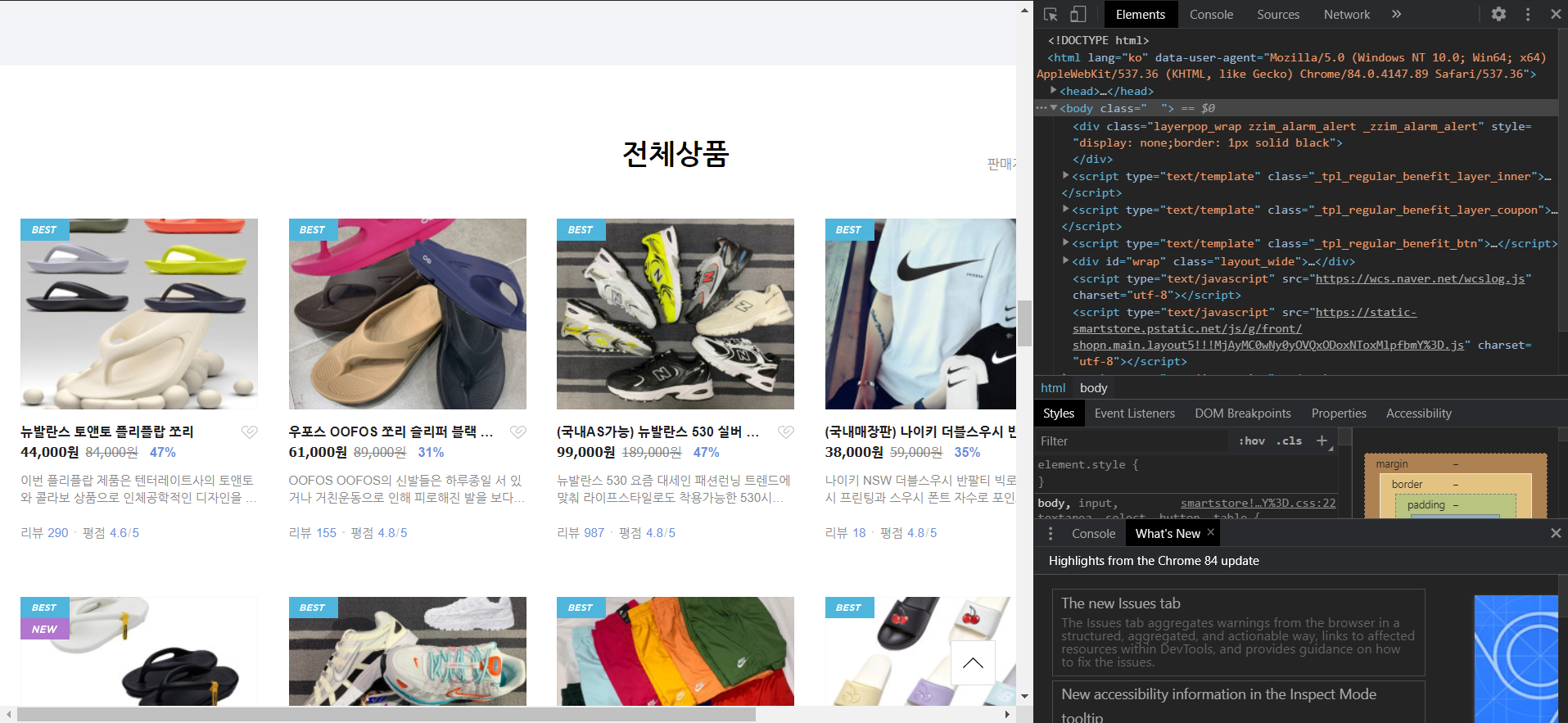
전체상품 페이지에서 상품 정보, 가격, 상품 정보를 간략히 보여주고 있습니다.
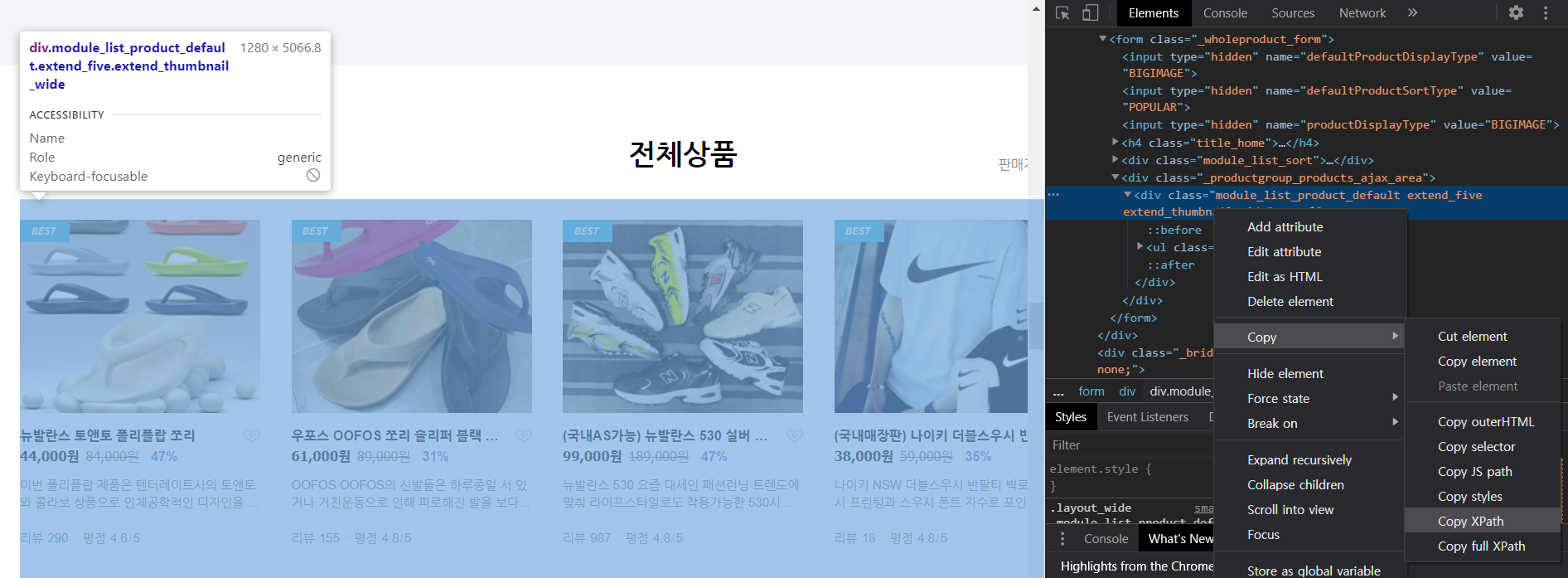
전체 상품은 div태그의 class명으로 module_list_product_default extend_five extend_thumbnail_wide란 이름을 갖고 있습니다. 이 부분에서 오른쪽 마우스 클릭, Copy에 Copy XPath를 눌러줍니다.
그럼 //*[@id="content"]/form/div[2]/div 라는 XPath 위치 정보를 갖고 있는 것을 알 수 있습니다. 그리고 그 안에 <li>태그로 각 상품의 정보를 담고 있는 것을 알 수 있습니다.
이제 python 코드를 작성해 보겠습니다. 먼저 모든 상품정보를 담을 수 있는 클래스 생성해 보겠습니다.
상품정보 클래스에는 다음과 같은 정보를 넣습니다.
- 상품명
- 할인 가격
- 원 가격
- 할인률
- 제품 상세 링크
그리고 getter 메서드를 생성해줍니다.
#-*- coding: utf-8 -*-
# goods.py
class Goods:
# 상품정보 클래스
def __init__(self,
goods_name,
discounted_price,
original_price,
discount_rate,
goods_link):
self._goods_name = goods_name
self._discounted_price = discounted_price
self._original_price = original_ice
self._discount_rate = discount_rate
self._goods_link = goods_link
def getGoodsName(self):
return self._goods_name
def getDiscountedPrice(self):
return self._discounted_price
def getOriginalPrice(self):
return self._original_price
def getDiscountRate(self):
return self._discount_rate
def getGoodsLink(self):
return self._goods_link
def __str__(self):
return "************\n상품명: {}\n할인된 가격: {}\n원 가: {}\n할인률: {}\n상품 링크: {}\n************\n".format(
self._goods_name,
self._discounted_price,
self._original_price,
self._discount_rate,
self._goods_link
)
상품정보 클래스 생성 후, 전체상품을 크롤링하는 함수를 작성합니다. selenium의 driver를 인자로 받습니다. 아까 복사해둔 XPath를 driver의 find_element_by_xpath인자로 넣어줍니다. BeautifulSoup으로 HTML 을 parsing해줍니다. 이제 전체 상품정보의 각 상품의 간략한 정보를 가져옵니다. 전체 상품은 <li>로 구성되어 있기 때문에 select함수를 사용하여 <li>태그가 붙은 모든 정보를 가져옵니다. 이제 각 상품의 세세한 정보를 가져올 수 있게 합니다.
#-*- coding:utf-8 -*-
# goods.py
from bs4 import BeautifulSoup
def goodsALL(driver):
url = 'https://smartstore.naver.com'
goods_xpath = driver.find_element_by_xpath('//*[@id="content"]/form/div[2]/div')
soup = BeautifulSoup(goods_xpath.get_attribute('innerHTML'), 'html.parser')
goods = soup.select('li')
goods_list = []
for a_tag in goods:
link = a_tag.select('a.area_overview')[0].attrs['href']
good_info = [info.text for in a_tag.select('strong')]
good_info.append(url + link)
good = Goods(*good_info)
goods_list.append(good)
return goods_list
for문 안에 good_info라는 변수에 정보를 담고 Goods 객체를 생성합니다. 그리고 모든 Goods객체를 list형태로 묶어서 반환합니다.
3. 상세 상품 보기
상품 Link를 통해서 상품의 자세한 정보를 크롤링해보겠습니다.
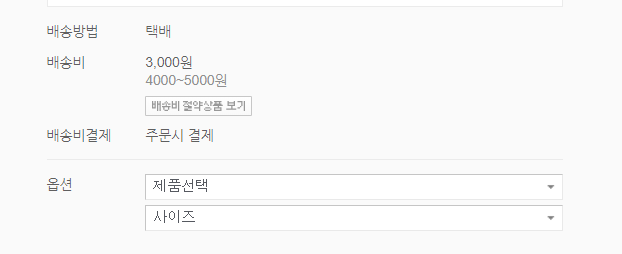
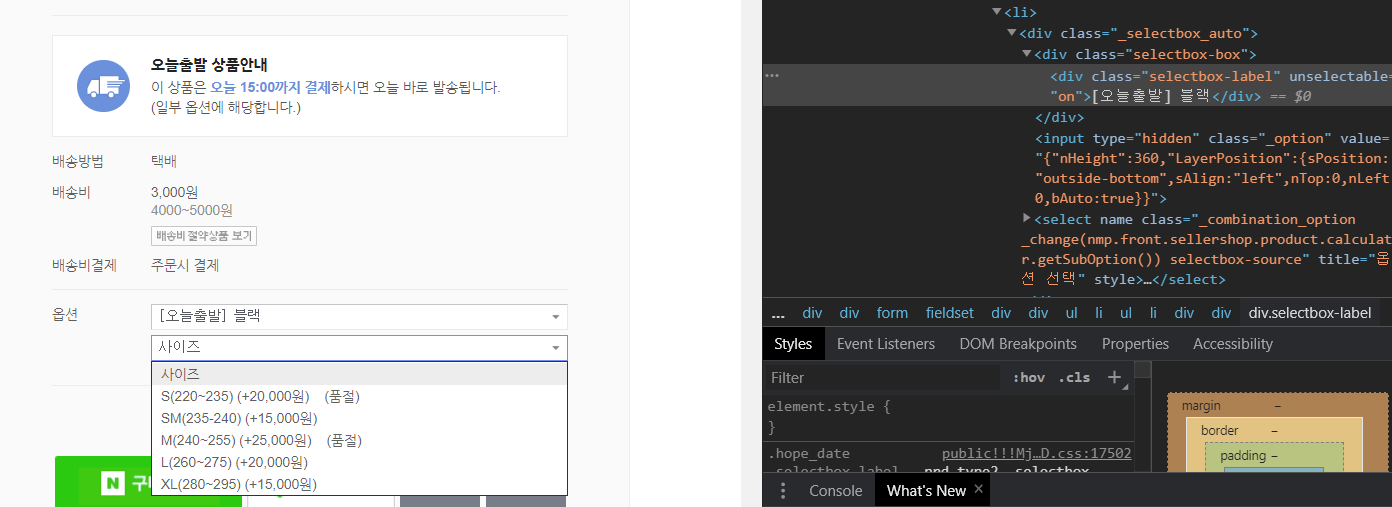
상품 정보는 다음과 같이 옵션이란 곳에 SelectBox로 구성되어 있습니다.
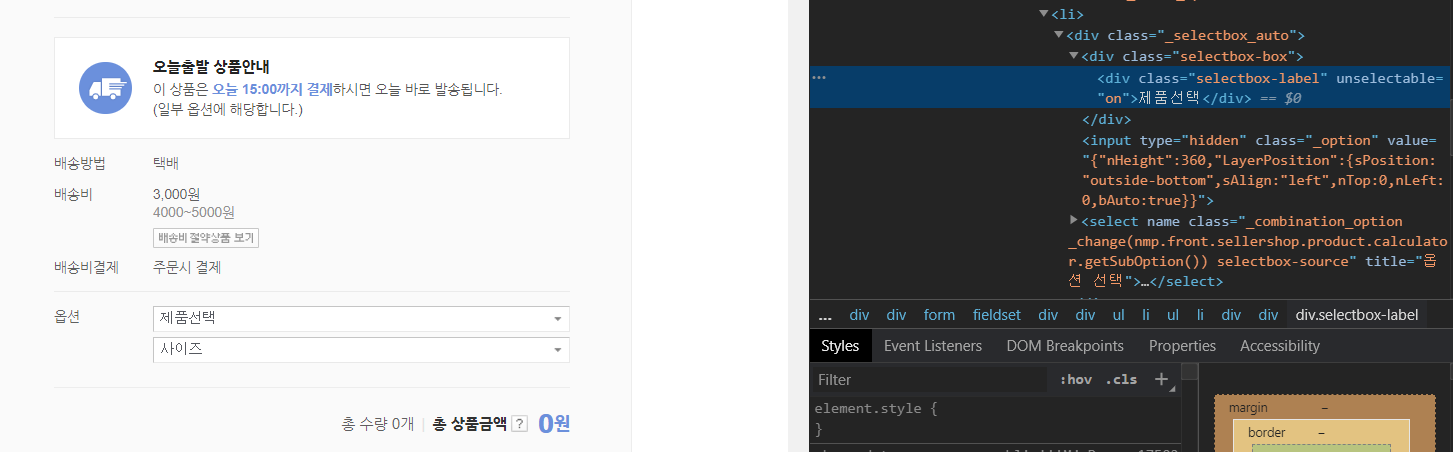
상품의 정보를 확인해보면 SelectBox 안의 정보를 확인할 수 없습니다. javascript로 되어 있기 때문에 Selenium을 통해 크롤링합니다. 그리고 우선 제품선택 후, 두 번째 옵션인 사이즈 정보를 볼 수 있습니다.
오타 등 언제든 말씀해주십시오. 글 읽어 주셔서 감사합니다.


Comments